33. Estimation of Spectra#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install --upgrade quantecon
33.1. Overview#
In a previous lecture, we covered some fundamental properties of covariance stationary linear stochastic processes.
One objective for that lecture was to introduce spectral densities — a standard and very useful technique for analyzing such processes.
In this lecture, we turn to the problem of estimating spectral densities and other related quantities from data.
Estimates of the spectral density are computed using what is known as a periodogram — which in turn is computed via the famous fast Fourier transform.
Once the basic technique has been explained, we will apply it to the analysis of several key macroeconomic time series.
For supplementary reading, see [Sargent, 1987] or [Cryer and Chan, 2008].
Let’s start with some standard imports:
import numpy as np
import matplotlib.pyplot as plt
from quantecon import ARMA, periodogram, ar_periodogram
33.2. Periodograms#
Recall that the spectral density \(f\) of a covariance stationary process with autocorrelation function \(\gamma\) can be written
Now consider the problem of estimating the spectral density of a given time series, when \(\gamma\) is unknown.
In particular, let \(X_0, \ldots, X_{n-1}\) be \(n\) consecutive observations of a single time series that is assumed to be covariance stationary.
The most common estimator of the spectral density of this process is the periodogram of \(X_0, \ldots, X_{n-1}\), which is defined as
(Recall that \(|z|\) denotes the modulus of complex number \(z\))
Alternatively, \(I(\omega)\) can be expressed as
It is straightforward to show that the function \(I\) is even and \(2 \pi\)-periodic (i.e., \(I(\omega) = I(-\omega)\) and \(I(\omega + 2\pi) = I(\omega)\) for all \(\omega \in \mathbb R\)).
From these two results, you will be able to verify that the values of \(I\) on \([0, \pi]\) determine the values of \(I\) on all of \(\mathbb R\).
The next section helps to explain the connection between the periodogram and the spectral density.
33.2.1. Interpretation#
To interpret the periodogram, it is convenient to focus on its values at the Fourier frequencies
In what sense is \(I(\omega_j)\) an estimate of \(f(\omega_j)\)?
The answer is straightforward, although it does involve some algebra.
With a bit of effort, one can show that for any integer \(j > 0\),
Letting \(\bar X\) denote the sample mean \(n^{-1} \sum_{t=0}^{n-1} X_t\), we then have
By carefully working through the sums, one can transform this to
Now let
This is the sample autocovariance function, the natural “plug-in estimator” of the autocovariance function \(\gamma\).
(“Plug-in estimator” is an informal term for an estimator found by replacing expectations with sample means)
With this notation, we can now write
Recalling our expression for \(f\) given above, we see that \(I(\omega_j)\) is just a sample analog of \(f(\omega_j)\).
33.2.2. Calculation#
Let’s now consider how to compute the periodogram as defined in (33.1).
There are already functions available that will do this for us
— an example is statsmodels.tsa.stattools.periodogram in the statsmodels package.
However, it is very simple to replicate their results, and this will give us a platform to make useful extensions.
The most common way to calculate the periodogram is via the discrete Fourier transform, which in turn is implemented through the fast Fourier transform algorithm.
In general, given a sequence \(a_0, \ldots, a_{n-1}\), the discrete Fourier transform computes the sequence
With numpy.fft.fft imported as fft and \(a_0, \ldots, a_{n-1}\) stored in NumPy array a, the function call fft(a) returns the values \(A_0, \ldots, A_{n-1}\) as a NumPy array.
It follows that when the data \(X_0, \ldots, X_{n-1}\) are stored in array X, the values \(I(\omega_j)\) at the Fourier frequencies, which are given by
can be computed by np.abs(fft(X))**2 / len(X).
Note
The NumPy function abs acts elementwise, and correctly handles complex numbers (by computing their modulus, which is exactly what we need).
A function called periodogram that puts all this together can be found here.
Let’s generate some data for this function using the ARMA class from QuantEcon.py (see the lecture on linear processes for more details).
Here’s a code snippet that, once the preceding code has been run, generates data from the process
where \(\{ \epsilon_t \}\) is white noise with unit variance, and compares the periodogram to the actual spectral density
n = 40 # Data size
ϕ, θ = 0.5, (0, -0.8) # AR and MA parameters
lp = ARMA(ϕ, θ)
X = lp.simulation(ts_length=n)
fig, ax = plt.subplots()
x, y = periodogram(X)
ax.plot(x, y, 'b-', lw=2, alpha=0.5, label='periodogram')
x_sd, y_sd = lp.spectral_density(two_pi=False, res=120)
ax.plot(x_sd, y_sd, 'r-', lw=2, alpha=0.8, label='spectral density')
ax.legend()
plt.show()
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/matplotlib/cbook.py:1719: ComplexWarning: Casting complex values to real discards the imaginary part
return math.isfinite(val)
/home/runner/miniconda3/envs/quantecon/lib/python3.13/site-packages/matplotlib/cbook.py:1355: ComplexWarning: Casting complex values to real discards the imaginary part
return np.asarray(x, float)
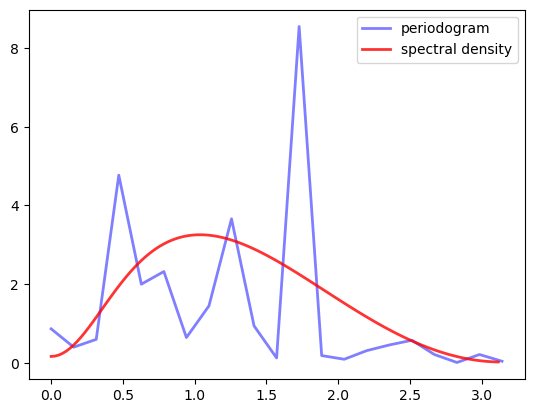
This estimate looks rather disappointing, but the data size is only 40, so perhaps it’s not surprising that the estimate is poor.
However, if we try again with n = 1200 the outcome is not much better
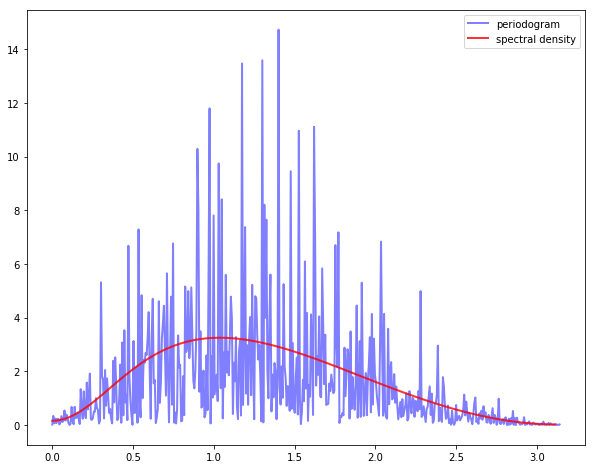
The periodogram is far too irregular relative to the underlying spectral density.
This brings us to our next topic.
33.3. Smoothing#
There are two related issues here.
One is that, given the way the fast Fourier transform is implemented, the number of points \(\omega\) at which \(I(\omega)\) is estimated increases in line with the amount of data.
In other words, although we have more data, we are also using it to estimate more values.
A second issue is that densities of all types are fundamentally hard to estimate without parametric assumptions.
Typically, nonparametric estimation of densities requires some degree of smoothing.
The standard way that smoothing is applied to periodograms is by taking local averages.
In other words, the value \(I(\omega_j)\) is replaced with a weighted average of the adjacent values
This weighted average can be written as
where the weights \(w(-p), \ldots, w(p)\) are a sequence of \(2p + 1\) nonnegative values summing to one.
In general, larger values of \(p\) indicate more smoothing — more on this below.
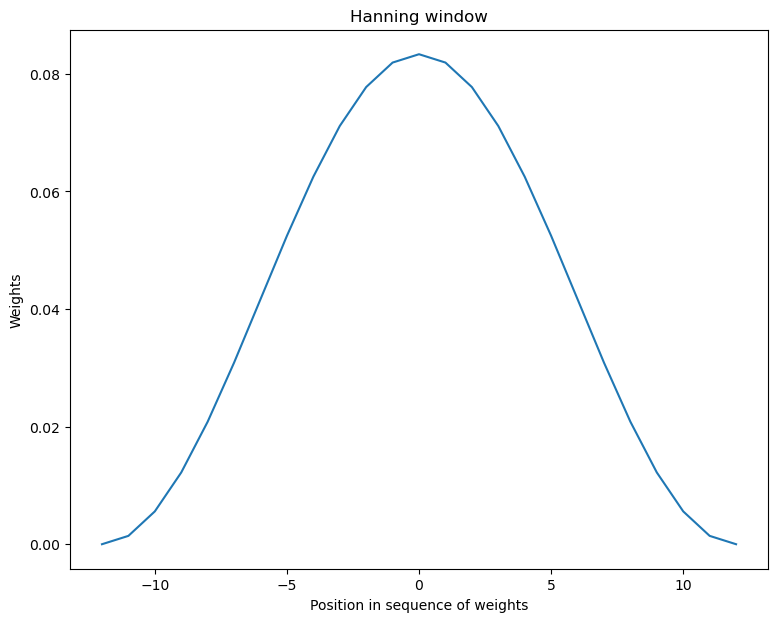
The next figure shows the kind of sequence typically used.
Note the smaller weights towards the edges and larger weights in the center, so that more distant values from \(I(\omega_j)\) have less weight than closer ones in the sum (33.3).
def hanning_window(M):
w = [0.5 - 0.5 * np.cos(2 * np.pi * n/(M-1)) for n in range(M)]
return w
window = hanning_window(25) / np.abs(sum(hanning_window(25)))
x = np.linspace(-12, 12, 25)
fig, ax = plt.subplots(figsize=(9, 7))
ax.plot(x, window)
ax.set_title("Hanning window")
ax.set_ylabel("Weights")
ax.set_xlabel("Position in sequence of weights")
plt.show()
33.3.1. Estimation with smoothing#
Our next step is to provide code that will not only estimate the periodogram but also provide smoothing as required.
Such functions have been written in estspec.py and are available once you’ve installed QuantEcon.py.
The GitHub listing displays three functions, smooth(), periodogram(), ar_periodogram(). We will discuss the first two here and the third one below.
The periodogram() function returns a periodogram, optionally smoothed via the smooth() function.
Regarding the smooth() function, since smoothing adds a nontrivial amount of computation, we have applied a fairly terse array-centric method based around np.convolve.
Readers are left either to explore or simply to use this code according to their interests.
The next three figures each show smoothed and unsmoothed periodograms, as well as the population or “true” spectral density.
(The model is the same as before — see equation (33.2) — and there are 400 observations)
From the top figure to bottom, the window length is varied from small to large.
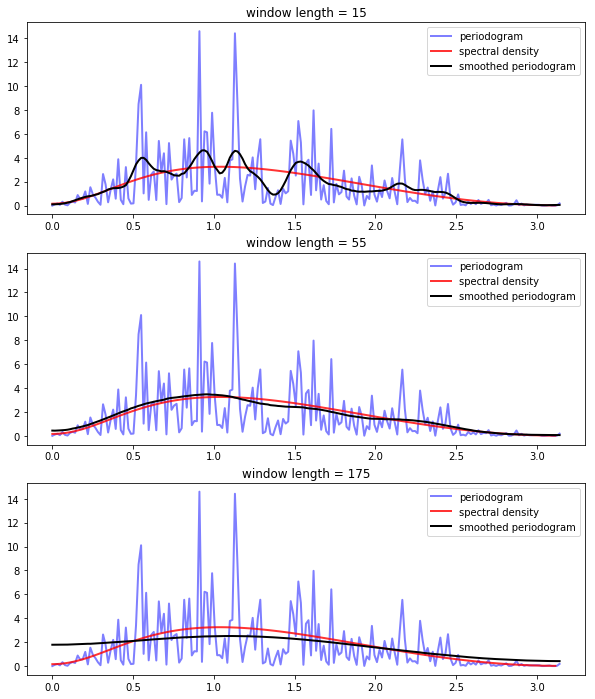
In looking at the figure, we can see that for this model and data size, the window length chosen in the middle figure provides the best fit.
Relative to this value, the first window length provides insufficient smoothing, while the third gives too much smoothing.
Of course in real estimation problems, the true spectral density is not visible and the choice of appropriate smoothing will have to be made based on judgement/priors or some other theory.
33.3.2. Pre-filtering and smoothing#
In the code listing, we showed three functions from the file estspec.py.
The third function in the file (ar_periodogram()) adds a pre-processing step to periodogram smoothing.
First, we describe the basic idea, and after that we give the code.
The essential idea is to
Transform the data in order to make estimation of the spectral density more efficient.
Compute the periodogram associated with the transformed data.
Reverse the effect of the transformation on the periodogram, so that it now estimates the spectral density of the original process.
Step 1 is called pre-filtering or pre-whitening, while step 3 is called recoloring.
The first step is called pre-whitening because the transformation is usually designed to turn the data into something closer to white noise.
Why would this be desirable in terms of spectral density estimation?
The reason is that we are smoothing our estimated periodogram based on estimated values at nearby points — recall (33.3).
The underlying assumption that makes this a good idea is that the true spectral density is relatively regular — the value of \(I(\omega)\) is close to that of \(I(\omega')\) when \(\omega\) is close to \(\omega'\).
This will not be true in all cases, but it is certainly true for white noise.
For white noise, \(I\) is as regular as possible — it is a constant function.
In this case, values of \(I(\omega')\) at points \(\omega'\) near to \(\omega\) provided the maximum possible amount of information about the value \(I(\omega)\).
Another way to put this is that if \(I\) is relatively constant, then we can use a large amount of smoothing without introducing too much bias.
33.3.3. The AR(1) setting#
Let’s examine this idea more carefully in a particular setting — where the data are assumed to be generated by an AR(1) process.
(More general ARMA settings can be handled using similar techniques to those described below)
Suppose in particular that \(\{X_t\}\) is covariance stationary and AR(1), with
where \(\mu\) and \(\phi \in (-1, 1)\) are unknown parameters and \(\{ \epsilon_t \}\) is white noise.
It follows that if we regress \(X_{t+1}\) on \(X_t\) and an intercept, the residuals will approximate white noise.
Let
\(g\) be the spectral density of \(\{ \epsilon_t \}\) — a constant function, as discussed above
\(I_0\) be the periodogram estimated from the residuals — an estimate of \(g\)
\(f\) be the spectral density of \(\{ X_t \}\) — the object we are trying to estimate
In view of an earlier result we obtained while discussing ARMA processes, \(f\) and \(g\) are related by
This suggests that the recoloring step, which constructs an estimate \(I\) of \(f\) from \(I_0\), should set
where \(\hat \phi\) is the OLS estimate of \(\phi\).
The code for ar_periodogram() — the third function in estspec.py — does exactly this. (See the code here).
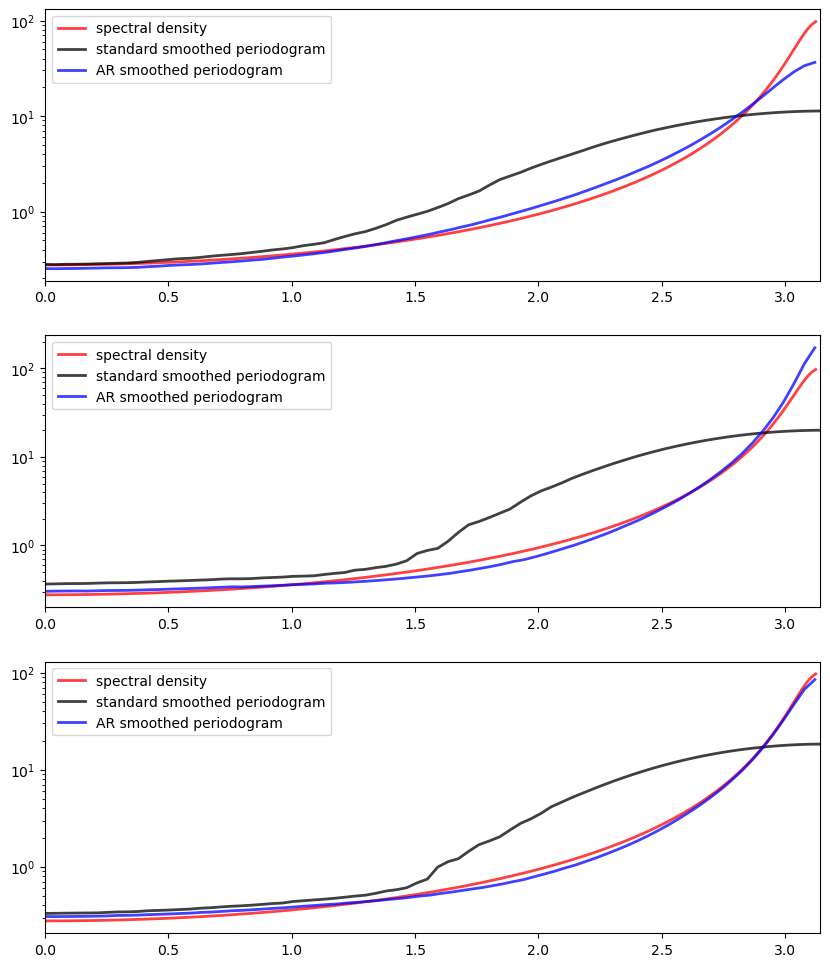
The next figure shows realizations of the two kinds of smoothed periodograms
“standard smoothed periodogram”, the ordinary smoothed periodogram, and
“AR smoothed periodogram”, the pre-whitened and recolored one generated by
ar_periodogram()
The periodograms are calculated from time series drawn from (33.4) with \(\mu = 0\) and \(\phi = -0.9\).
Each time series is of length 150.
The difference between the three subfigures is just randomness — each one uses a different draw of the time series.
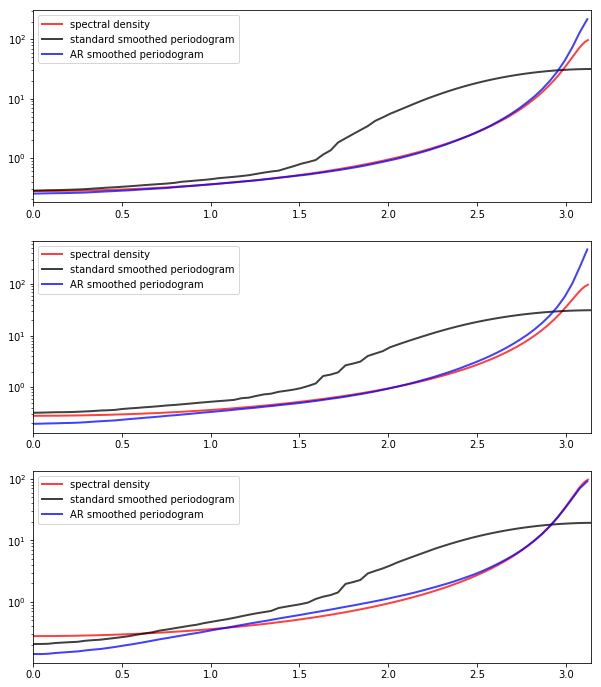
In all cases, periodograms are fit with the “hamming” window and window length of 65.
Overall, the fit of the AR smoothed periodogram is much better, in the sense of being closer to the true spectral density.
33.4. Exercises#
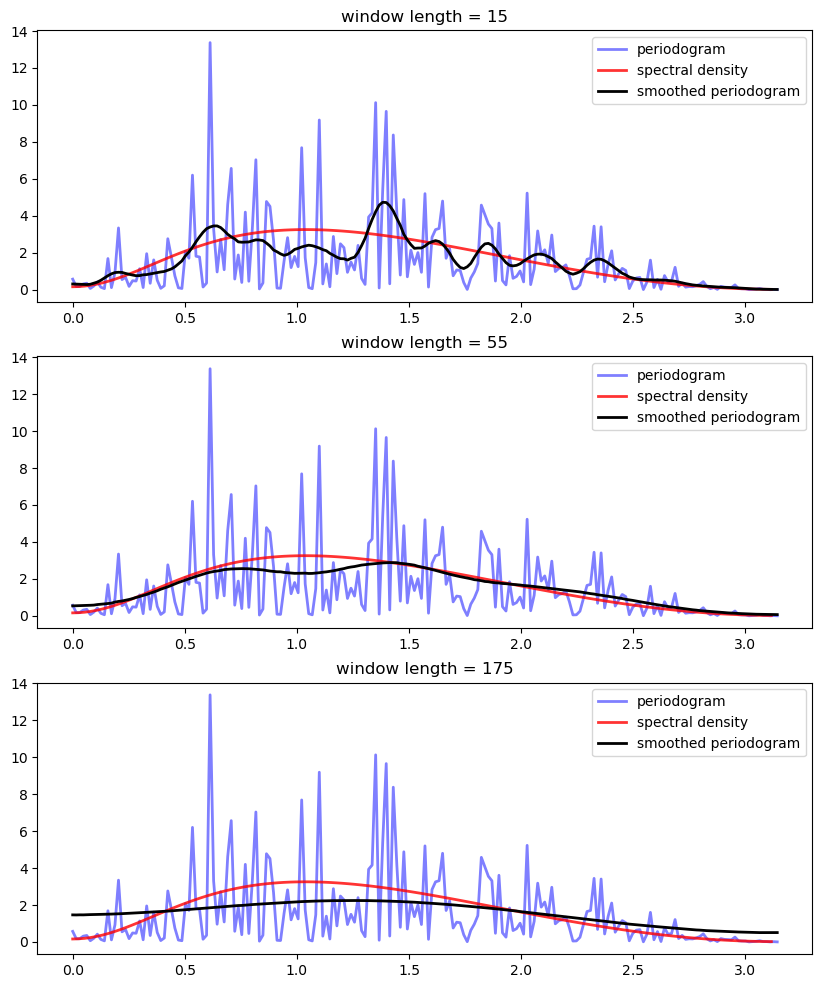
Exercise 33.1
Replicate this figure (modulo randomness).
The model is as in equation (33.2) and there are 400 observations.
For the smoothed periodogram, the window type is “hamming”.
Solution
## Data
n = 400
ϕ = 0.5
θ = 0, -0.8
lp = ARMA(ϕ, θ)
X = lp.simulation(ts_length=n)
fig, ax = plt.subplots(3, 1, figsize=(10, 12))
for i, wl in enumerate((15, 55, 175)): # Window lengths
x, y = periodogram(X)
ax[i].plot(x, y, 'b-', lw=2, alpha=0.5, label='periodogram')
x_sd, y_sd = lp.spectral_density(two_pi=False, res=120)
ax[i].plot(x_sd, y_sd, 'r-', lw=2, alpha=0.8, label='spectral density')
x, y_smoothed = periodogram(X, window='hamming', window_len=wl)
ax[i].plot(x, y_smoothed, 'k-', lw=2, label='smoothed periodogram')
ax[i].legend()
ax[i].set_title(f'window length = {wl}')
plt.show()
Exercise 33.2
Replicate this figure (modulo randomness).
The model is as in equation (33.4), with \(\mu = 0\), \(\phi = -0.9\) and 150 observations in each time series.
All periodograms are fit with the “hamming” window and window length of 65.
Solution
lp = ARMA(-0.9)
wl = 65
fig, ax = plt.subplots(3, 1, figsize=(10,12))
for i in range(3):
X = lp.simulation(ts_length=150)
ax[i].set_xlim(0, np.pi)
x_sd, y_sd = lp.spectral_density(two_pi=False, res=180)
ax[i].semilogy(x_sd, y_sd, 'r-', lw=2, alpha=0.75,
label='spectral density')
x, y_smoothed = periodogram(X, window='hamming', window_len=wl)
ax[i].semilogy(x, y_smoothed, 'k-', lw=2, alpha=0.75,
label='standard smoothed periodogram')
x, y_ar = ar_periodogram(X, window='hamming', window_len=wl)
ax[i].semilogy(x, y_ar, 'b-', lw=2, alpha=0.75,
label='AR smoothed periodogram')
ax[i].legend(loc='upper left')
plt.show()