1. Orthogonal Projections and Their Applications#
1.1. Overview#
Orthogonal projection is a cornerstone of vector space methods, with many diverse applications.
These include
Least squares projection, also known as linear regression
Conditional expectations for multivariate normal (Gaussian) distributions
Gram–Schmidt orthogonalization
QR decomposition
Orthogonal polynomials
etc
In this lecture, we focus on
key ideas
least squares regression
We’ll require the following imports:
import numpy as np
from scipy.linalg import qr
1.1.1. Further reading#
For background and foundational concepts, see our lecture on linear algebra.
For more proofs and greater theoretical detail, see A Primer in Econometric Theory.
For a complete set of proofs in a general setting, see, for example, [Roman, 2005].
For an advanced treatment of projection in the context of least squares prediction, see this book chapter.
1.2. Key definitions#
Assume \(x, z \in \mathbb R^n\).
Define \(\langle x, z\rangle = \sum_i x_i z_i\).
Recall \(\|x \|^2 = \langle x, x \rangle\).
The law of cosines states that \(\langle x, z \rangle = \| x \| \| z \| \cos(\theta)\) where \(\theta\) is the angle between the vectors \(x\) and \(z\).
When \(\langle x, z\rangle = 0\), then \(\cos(\theta) = 0\) and \(x\) and \(z\) are said to be orthogonal and we write \(x \perp z\).
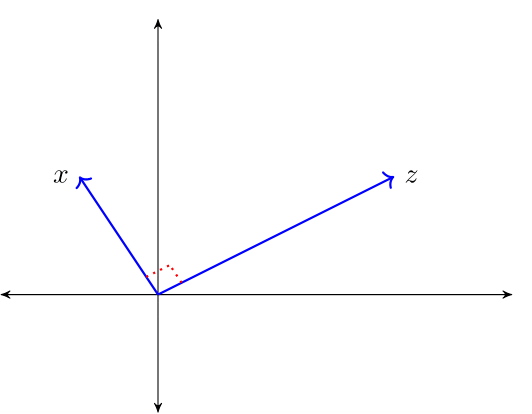
For a linear subspace \(S \subset \mathbb R^n\), we call \(x \in \mathbb R^n\) orthogonal to \(S\) if \(x \perp z\) for all \(z \in S\), and write \(x \perp S\).
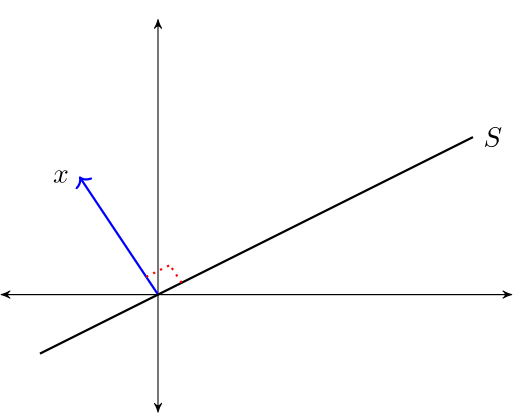
The orthogonal complement of linear subspace \(S \subset \mathbb R^n\) is the set \(S^{\perp} := \{x \in \mathbb R^n \,:\, x \perp S\}\).
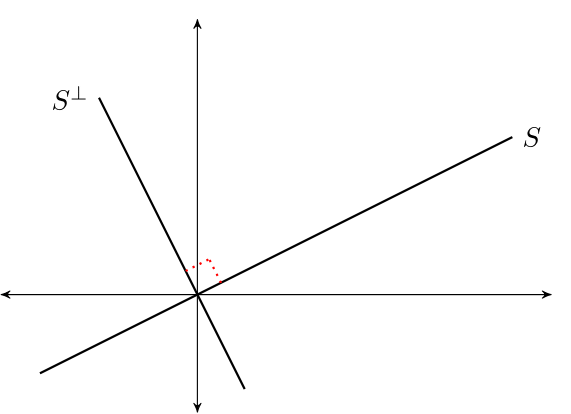
\(S^\perp\) is a linear subspace of \(\mathbb R^n\)
To see this, fix \(x, y \in S^{\perp}\) and \(\alpha, \beta \in \mathbb R\).
Observe that if \(z \in S\), then
Hence \(\alpha x + \beta y \in S^{\perp}\), as was to be shown
A set of vectors \(\{x_1, \ldots, x_k\} \subset \mathbb R^n\) is called an orthogonal set if \(x_i \perp x_j\) whenever \(i \not= j\).
If \(\{x_1, \ldots, x_k\}\) is an orthogonal set, then the Pythagorean Law states that
For example, when \(k=2\), \(x_1 \perp x_2\) implies
1.2.1. Linear independence vs orthogonality#
If \(X \subset \mathbb R^n\) is an orthogonal set and \(0 \notin X\), then \(X\) is linearly independent.
Proving this is a nice exercise.
While the converse is not true, a kind of partial converse holds, as we’ll see below.
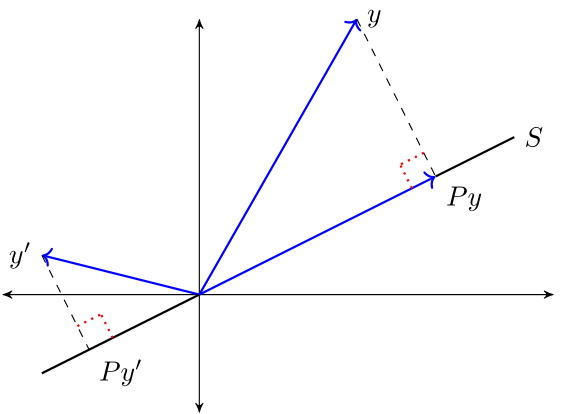
1.3. The orthogonal projection theorem#
What vector within a linear subspace of \(\mathbb R^n\) best approximates a given vector in \(\mathbb R^n\)?
The next theorem answers this question.
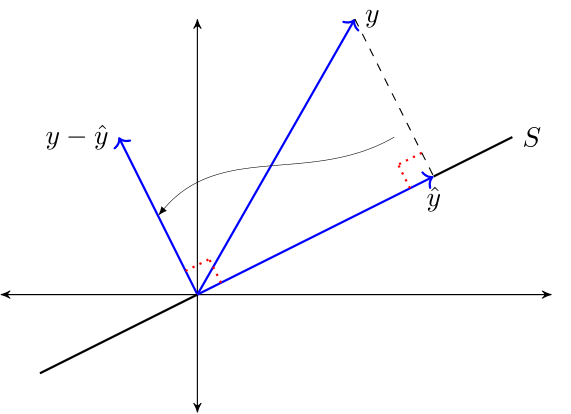
Theorem 1.1 (Orthogonal Projection Theorem)
Given \(y \in \mathbb R^n\) and linear subspace \(S \subset \mathbb R^n\), there exists a unique solution to the minimization problem
The minimizer \(\hat y\) is the unique vector in \(\mathbb R^n\) that satisfies
\(\hat y \in S\)
\(y - \hat y \perp S\)
The vector \(\hat y\) is called the orthogonal projection of \(y\) onto \(S\).
The next figure provides some intuition
1.3.1. Proof of sufficiency#
We’ll omit the full proof.
But we will prove sufficiency of the asserted conditions.
To this end, let \(y \in \mathbb R^n\) and let \(S\) be a linear subspace of \(\mathbb R^n\).
Let \(\hat y\) be a vector in \(\mathbb R^n\) such that \(\hat y \in S\) and \(y - \hat y \perp S\).
Let \(z\) be any other point in \(S\) and use the fact that \(S\) is a linear subspace to deduce
Hence \(\| y - z \| \geq \| y - \hat y \|\), which completes the proof.
1.3.2. Orthogonal projection as a mapping#
For a linear space \(Y\) and a fixed linear subspace \(S\), we have a functional relationship
By the Theorem 1.1, this is a well-defined mapping or operator from \(\mathbb R^n\) to \(\mathbb R^n\).
In what follows we denote this operator by a matrix \(P\)
\(P y\) represents the projection \(\hat y\).
This is sometimes expressed as \(\hat E_S y = P y\), where \(\hat E\) denotes a wide-sense expectations operator and the subscript \(S\) indicates that we are projecting \(y\) onto the linear subspace \(S\).
The operator \(P\) is called the orthogonal projection mapping onto \(S\).
It is immediate from the Theorem 1.1 that for any \(y \in \mathbb R^n\)
\(P y \in S\) and
\(y - P y \perp S\)
From this, we can deduce additional useful properties, such as
\(\| y \|^2 = \| P y \|^2 + \| y - P y \|^2\) and
\(\| P y \| \leq \| y \|\)
For example, to prove 1, observe that \(y = P y + y - P y\) and apply the Pythagorean law.
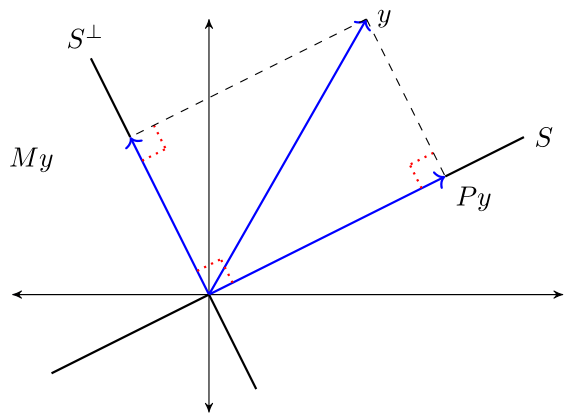
1.3.2.1. Orthogonal complement#
Let \(S \subset \mathbb R^n\).
The orthogonal complement of \(S\) is the linear subspace \(S^{\perp}\) that satisfies \(x_1 \perp x_2\) for every \(x_1 \in S\) and \(x_2 \in S^{\perp}\).
Let \(Y\) be a linear space with linear subspace \(S\) and its orthogonal complement \(S^{\perp}\).
We write
to indicate that for every \(y \in Y\) there is unique \(x_1 \in S\) and a unique \(x_2 \in S^{\perp}\) such that \(y = x_1 + x_2\).
Moreover, \(x_1 = \hat E_S y\) and \(x_2 = y - \hat E_S y\).
This amounts to another version of the Theorem 1.1:
Theorem 1.2 (Orthogonal Projection Theorem (another version))
If \(S\) is a linear subspace of \(\mathbb R^n\), \(\hat E_S y = P y\) and \(\hat E_{S^{\perp}} y = M y\), then
The next figure illustrates
1.4. Orthonormal basis#
An orthogonal set of vectors \(O \subset \mathbb R^n\) is called an orthonormal set if \(\| u \| = 1\) for all \(u \in O\).
Let \(S\) be a linear subspace of \(\mathbb R^n\) and let \(O \subset S\).
If \(O\) is orthonormal and \(\mathop{\mathrm{span}} O = S\), then \(O\) is called an orthonormal basis of \(S\).
\(O\) is necessarily a basis of \(S\) (being independent by orthogonality and the fact that no element is the zero vector).
One example of an orthonormal set is the canonical basis \(\{e_1, \ldots, e_n\}\) that forms an orthonormal basis of \(\mathbb R^n\), where \(e_i\) is the \(i\) th unit vector.
If \(\{u_1, \ldots, u_k\}\) is an orthonormal basis of linear subspace \(S\), then
To see this, observe that since \(x \in \mathop{\mathrm{span}}\{u_1, \ldots, u_k\}\), we can find scalars \(\alpha_1, \ldots, \alpha_k\) that verify
Taking the inner product with respect to \(u_i\) gives
Combining this result with (1.1) verifies the claim.
1.4.1. Projection onto an orthonormal basis#
When a subspace onto which we project is orthonormal, computing the projection simplifies:
Theorem 1.3
If \(\{u_1, \ldots, u_k\}\) is an orthonormal basis for \(S\), then
Proof. Fix \(y \in \mathbb{R}^n\) and let \(P y\) be defined as in (1.2).
Clearly, \(P y \in S\).
We claim that \(y - P y \perp S\) also holds.
It suffices to show that \(y - P y \perp u_i\) for any basis vector \(u_i\).
This is true because
(Why is this sufficient to establish the claim that \(y - P y \perp S\)?)
1.5. Projection via matrix algebra#
Let \(S\) be a linear subspace of \(\mathbb R^n\) and let \(y \in \mathbb R^n\).
We want to compute the matrix \(P\) that verifies
Evidently \(Py\) is a linear function from \(y \in \mathbb R^n\) to \(P y \in \mathbb R^n\).
This reference is useful.
Theorem 1.4
Let the columns of \(n \times k\) matrix \(X\) form a basis of \(S\). Then
Proof. Given arbitrary \(y \in \mathbb R^n\) and \(P = X (X'X)^{-1} X'\), our claim is that
\(P y \in S\), and
\(y - P y \perp S\)
Claim 1 is true because
An expression of the form \(X a\) is precisely a linear combination of the columns of \(X\) and hence an element of \(S\).
Claim 2 is equivalent to the statement
To verify this, notice that if \(b \in \mathbb R^K\), then
The proof is now complete.
1.5.1. Starting with the basis#
It is common in applications to start with \(n \times k\) matrix \(X\) with linearly independent columns and let
Then the columns of \(X\) form a basis of \(S\).
From the Theorem 1.4, \(P = X (X' X)^{-1} X' y\) projects \(y\) onto \(S\).
In this context, \(P\) is often called the projection matrix
The matrix \(M = I - P\) satisfies \(M y = \hat E_{S^{\perp}} y\) and is sometimes called the annihilator matrix.
1.5.2. The orthonormal case#
Suppose that \(U\) is \(n \times k\) with orthonormal columns.
Let \(u_i := \mathop{\mathrm{col}}_i U\) for each \(i\), let \(S := \mathop{\mathrm{span}} U\) and let \(y \in \mathbb R^n\).
We know that the projection of \(y\) onto \(S\) is
Since \(U\) has orthonormal columns, we have \(U' U = I\).
Hence
We have recovered our earlier result about projecting onto the span of an orthonormal basis.
1.5.3. Application: overdetermined systems of equations#
Let \(y \in \mathbb R^n\) and let \(X\) be \(n \times k\) with linearly independent columns.
Given \(X\) and \(y\), we seek \(b \in \mathbb R^k\) that satisfies the system of linear equations \(X b = y\).
If \(n > k\) (more equations than unknowns), then the system is said to be overdetermined.
Intuitively, we may not be able to find a \(b\) that satisfies all \(n\) equations.
The best approach here is to
Accept that an exact solution may not exist.
Look instead for an approximate solution.
By approximate solution, we mean a \(b \in \mathbb R^k\) such that \(X b\) is close to \(y\).
The next theorem shows that a best approximation is well defined and unique.
The proof uses the Theorem 1.1.
Theorem 1.5
The unique minimizer of \(\| y - X b \|\) over \(b \in \mathbb R^k\) is
Proof. Note that
Since \(P y\) is the orthogonal projection onto \(\mathop{\mathrm{span}}(X)\) we have
Because \(Xb \in \mathop{\mathrm{span}}(X)\)
This is what we aimed to show.
1.6. Least squares regression#
Let’s apply the theory of orthogonal projection to least squares regression.
This approach provides insights about many geometric properties of linear regression.
We treat only some examples.
1.6.1. Squared risk measures#
Given pairs \((x, y) \in \mathbb R^K \times \mathbb R\), consider choosing \(f \colon \mathbb R^K \to \mathbb R\) to minimize the risk
If probabilities and hence \(\mathbb{E}\,\) are unknown, we cannot solve this problem directly.
However, if a sample is available, we can estimate the risk with the empirical risk:
Minimizing this expression is called empirical risk minimization.
The set \(\mathcal{F}\) is sometimes called the hypothesis space.
The theory of statistical learning tells us that to prevent overfitting we should take the set \(\mathcal{F}\) to be relatively simple.
If we let \(\mathcal{F}\) be the class of linear functions, the problem is
This is the sample linear least squares problem.
1.6.2. Solution#
Define the matrices
and
We assume throughout that \(N > K\) and \(X\) is full column rank.
If you work through the algebra, you will be able to verify that \(\| y - X b \|^2 = \sum_{n=1}^N (y_n - b' x_n)^2\).
Since monotone transforms don’t affect minimizers, we have
By our results about overdetermined linear systems of equations, the solution is
Let \(P\) and \(M\) be the projection and annihilator associated with \(X\):
The vector of fitted values is
The vector of residuals is
Here are some more standard definitions:
The total sum of squares is \(:= \| y \|^2\).
The sum of squared residuals is \(:= \| \hat u \|^2\).
The explained sum of squares is \(:= \| \hat y \|^2\).
We can prove this easily using the Theorem 1.1.
From the Theorem 1.1 we have \(y = \hat y + \hat u\) and \(\hat u \perp \hat y\).
Applying the Pythagorean law completes the proof.
1.7. Orthogonalization and decomposition#
Let’s return to the connection between linear independence and orthogonality touched on above.
A result of much interest is a famous algorithm for constructing orthonormal sets from linearly independent sets.
The next section gives details.
1.7.1. Gram-Schmidt orthogonalization#
Theorem 1.6
For each linearly independent set \(\{x_1, \ldots, x_k\} \subset \mathbb R^n\), there exists an orthonormal set \(\{u_1, \ldots, u_k\}\) with
The Gram-Schmidt orthogonalization procedure constructs an orthogonal set \(\{ u_1, u_2, \ldots, u_n\}\).
One description of this procedure is as follows:
For \(i = 1, \ldots, k\), form \(S_i := \mathop{\mathrm{span}}\{x_1, \ldots, x_i\}\) and \(S_i^{\perp}\)
Set \(v_1 = x_1\)
For \(i \geq 2\) set \(v_i := \hat E_{S_{i-1}^{\perp}} x_i\) and \(u_i := v_i / \| v_i \|\)
The sequence \(u_1, \ldots, u_k\) has the stated properties.
A Gram-Schmidt orthogonalization construction is a key idea behind the Kalman filter described in A First Look at the Kalman filter.
In some exercises below, you are asked to implement this algorithm and test it using projection.
1.7.2. QR decomposition#
The following result uses the preceding algorithm to produce a useful decomposition.
Theorem 1.7
If \(X\) is \(n \times k\) with linearly independent columns, then there exists a factorization \(X = Q R\) where
\(R\) is \(k \times k\), upper triangular, and nonsingular
\(Q\) is \(n \times k\) with orthonormal columns
Proof. Let
\(x_j := \mathop{\mathrm{col}}_j (X)\)
\(\{u_1, \ldots, u_k\}\) be orthonormal with the same span as \(\{x_1, \ldots, x_k\}\) (to be constructed using Gram–Schmidt)
\(Q\) be formed from columns \(u_i\)
Since \(x_j \in \mathop{\mathrm{span}}\{u_1, \ldots, u_j\}\), we have
Some rearranging gives \(X = Q R\).
1.7.3. Linear regression via QR decomposition#
For matrices \(X\) and \(y\) that overdetermine \(\beta\) in the linear equation system \(y = X \beta\), we found the least squares approximator \(\hat \beta = (X' X)^{-1} X' y\).
Using the QR decomposition \(X = Q R\) gives
where the last step uses the fact that \((R' R)^{-1} R' = R^{-1}\) since \(R\) is nonsingular.
Numerical routines would in this case use the alternative form \(R \hat \beta = Q' y\) and back substitution.
1.8. Exercises#
Exercise 1.1
Show that, for any linear subspace \(S \subset \mathbb R^n\), \(S \cap S^{\perp} = \{0\}\).
Solution
If \(x \in S\) and \(x \in S^\perp\), then we have in particular that \(\langle x, x \rangle = 0\), but then \(x = 0\).
Exercise 1.2
Let \(P = X (X' X)^{-1} X'\) and let \(M = I - P\). Show that \(P\) and \(M\) are both idempotent and symmetric. Can you give any intuition as to why they should be idempotent?
Solution
Symmetry and idempotence of \(M\) and \(P\) can be established using standard rules for matrix algebra.
The intuition behind idempotence of \(M\) and \(P\) is that both are orthogonal projections.
After a point is projected into a given subspace, applying the projection again makes no difference (A point inside the subspace is not shifted by orthogonal projection onto that space because it is already the closest point in the subspace to itself).
Exercise 1.3
Using Gram-Schmidt orthogonalization, produce a linear projection of \(y\) onto the column space of \(X\) and verify this using the projection matrix \(P := X (X' X)^{-1} X'\) and also using QR decomposition, where:
and
Solution
Here’s a function that computes the orthonormal vectors using the GS algorithm given in the lecture
def gram_schmidt(X):
"""
Implements Gram-Schmidt orthogonalization.
Parameters
----------
X : an n x k array with linearly independent columns
Returns
-------
U : an n x k array with orthonormal columns
"""
# Set up
n, k = X.shape
U = np.empty((n, k))
I = np.eye(n)
# The first column of U is just the normalized first column of X
v1 = X[:, 0]
U[:, 0] = v1 / np.sqrt(np.sum(v1 * v1))
for i in range(1, k):
# Set up
b = X[:, i] # The vector we're going to project
Z = X[:, :i] # First i-1 columns of X
# Project onto the orthogonal complement of the columns span of Z
M = I - Z @ np.linalg.inv(Z.T @ Z) @ Z.T
u = M @ b
# Normalize
U[:, i] = u / np.sqrt(u @ u)
return U
Here are the arrays we’ll work with
y = [1, 3, -3]
X = [[1, 0],
[0, -6],
[2, 2]]
X, y = [np.asarray(z) for z in (X, y)]
First, let’s try projection of \(y\) onto the column space of \(X\) using the ordinary matrix expression:
Py1 = X @ np.linalg.inv(X.T @ X) @ X.T @ y
Py1
array([-0.56521739, 3.26086957, -2.2173913 ])
Now let’s do the same using an orthonormal basis created from our
gram_schmidt function
U = gram_schmidt(X)
U
array([[ 0.4472136 , -0.13187609],
[ 0. , -0.98907071],
[ 0.89442719, 0.06593805]])
Py2 = U @ U.T @ y
Py2
array([-0.56521739, 3.26086957, -2.2173913 ])
This is the same answer. So far so good. Finally, let’s try the same thing but with the basis obtained via QR decomposition:
Q, R = qr(X, mode='economic')
Q
array([[-0.4472136 , -0.13187609],
[-0. , -0.98907071],
[-0.89442719, 0.06593805]])
Py3 = Q @ Q.T @ y
Py3
array([-0.56521739, 3.26086957, -2.2173913 ])
Again, we obtain the same answer.